




AI and the Future of Code Reviews - A Deep Dive into CodeRabbitの意訳です。
ソフトウェア開発業界は今、転換期を迎えています。世界中の開発者がAIの持つ可能性に気づき始めており、GitHub CopilotやChatGPTの登場は、ソフトウェア開発に革命をもたらしました。これらのツールは、ソフトウェア開発の歴史上、最も急速に成長したものの一つです。
コード生成の分野では多くのツールが登場する一方で、コードレビューのプロセスはほとんど変化していません。私たちは依然として10年前と同じツールや手法を使い続けています。コードレビューは手作業で行われるため、時間がかかり、エラーが発生しやすく、コストも高くなりがちです。
この課題を解決するために、AIを活用したコードレビューツールCodeRabbitを開発しました。これはコードマージやCI/CDプロセスの一部として機能します。CodeRabbitを導入することで、コードマージのスピードを大幅に向上させるだけでなく、人間のレビュアーや既存のリンティングツールでは実現できないレベルまでコードの品質を引き上げることを目指しています。
品質の高いソフトウェアを高速にリリースする上での課題
開発者はコードの作成やレビューに多くの時間を費やしています。一般的な開発プロセスでは、メインのコードベースから分岐し、新機能の開発やバグ修正を行った後、コードをメインラインにマージします。開発には、Visual Studio Codeなどの最新エディターが活用され、言語サーバー、静的解析ツール、リンターなどが組み込まれています。さらに、GitHub CopilotのようなAI搭載の拡張機能が加わり、開発環境は急速に進化しています。しかし、ローカル開発ツールだけでは品質の確保には限界があります。
開発者ごとにツールの使い方や標準が異なるため、一貫性のある品質管理が難しくなります。そのため、GitHubやGitLabではプルリクエスト(PR)を活用し、コードを共同でマージします。PRを作成するとCI/CDプロセスが開始され、リントチェックやコンパイル、テストが実行されます。最も重要なのは、同僚によるコードレビューです。コーディング規約、セキュリティ脆弱性、その他の問題をチェックし、変更の意図が適切かどうかも確認されます。レビュー担当者がPRを承認すると、コードはメインのコードベースにマージされます。コードレビューは品質向上だけでなく、コンプライアンスや規制要件の遵守にも不可欠です。
理想的なコードレビュープロセスはスムーズで効率的ですが、現実には多くの課題があり、非効率的なことも少なくありません。特に、手動レビューは開発プロセスのボトルネックになりがちです。PRのマージに数日、場合によっては数週間かかることもあります。以下、主な課題を見ていきましょう。
チームの停滞: コードレビューやマージの待ち時間は、開発者だけでなくチーム全体に影響を及ぼします。スケジュールが遅れ、新機能のリリースやバグ修正が後回しになってしまいます。
コンテキストの切り替え: レビュー待ちの間に開発者が別の作業に取りかかると、元のコードの内容を忘れてしまいがちです。作業に戻る際には再びコードを理解し直す必要があり、生産性が低下します。
形式的なレビュー: チームが機能不全に陥ると、コードレビューが形骸化し、担当者が十分な確認をせずに承認してしまうことがあります。この結果、バグや脆弱性が見逃されるリスクが高まります。
開発者間の摩擦: コードの品質とは関係のない細かい指摘や意見の食い違いが原因で、レビューが長引くことがあります。これがチームの士気を下げ、職場環境の悪化につながることもあります。
仕事への不満: マージの遅れや非効率なプロセスが続くと、開発者のモチベーションが下がり、転職を考える要因になります。これにより、会社の定着率にも悪影響を及ぼします。
現在のコードレビューの課題は、ソフトウェア業界全体が抱える問題と直結しています。バグの多発、セキュリティの脆弱性、頻発するサービス停止といった問題の背景には、非効率な開発プロセスがあるのです。
CodeRabbitでコードを10倍高速にマージしよう
CodeRabbitは、コードレビューのスピードを大幅に向上させながら、コードの品質も高めるAI搭載のコードレビューツールです。プルリクエストのワークフローにシームレスに統合され、開発者とレビュー担当者が協力して品質を確保できます。従来のリンターや静的コード解析ツールを超え、コードの目的を人間のように理解し、問題点を明確にしながら改善策を提案します。
CodeRabbitを活用すれば、開発者は数分以内にコンテキストを理解したフィードバックを受け取れます。ベストプラクティスに基づいた提案に沿って修正を行うことで、より迅速にコードをマージできるようになります。また、レビュー担当者も、CodeRabbitが提供する自動生成のウォークスルーや提案を活用して、レビュー作業の負担を軽減できます。開発者とレビュー担当者、CodeRabbitの3者が連携してレビューの質が向上し、時間と労力の節約につながります。
CodeRabbitは生成AIを活用し、以下の機能を提供します。
要約: プルリクエストの変更点を要約し、高レベルの概要を提供します。これにより、レビュー担当者や製品チームは変更内容とその影響を素早く把握できます。
段階的なレビュー: コミットごとにコードを分析し、開発者に対して段階的なフィードバックを提供します。コード内にコメントを追加し、問題点や改善点を具体的に提示します。
変更に関するチャット: 開発者とレビュアーが直接質問したり、コードの修正提案を受けたりできる会話機能を提供します。これにより、変更内容の理解が深まり、効率的なコードレビューが可能になります。
CodeRabbitの設計
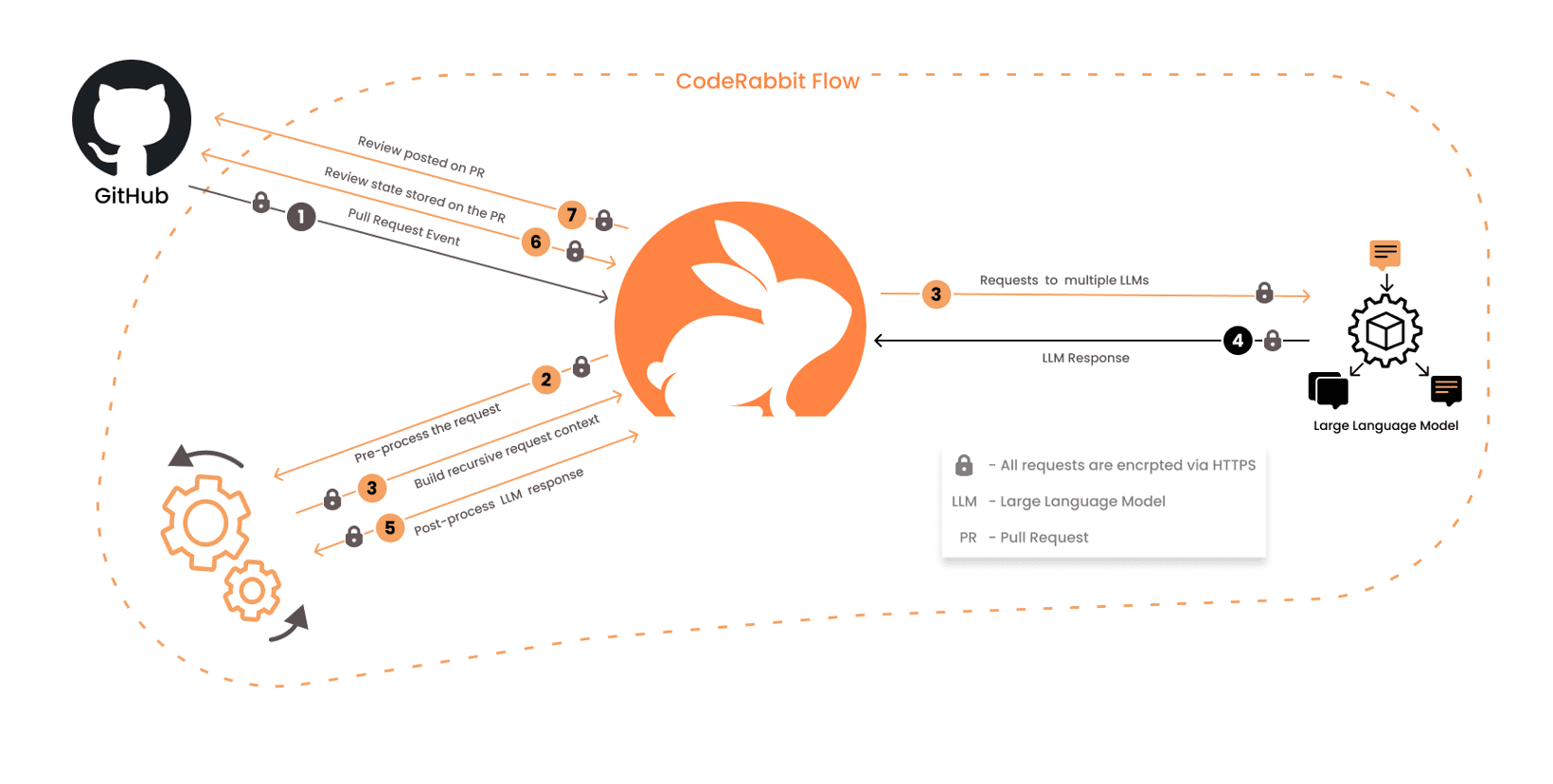
CodeRabbitのレビューは多段階のプロセスで進行し、以下の図のようにワークフローで設計されています。開発者がプルリクエストを開いたり、既存のプルリクエストにコードをコミットしたりすると、自動的にCodeRabbitが実行されます。その後、さまざまな要約とレビューのプロセスが行われます。

CodeRabbitは、単にLLM(大規模言語モデル)を利用だけではありません。コンテキストのサイズ制限を克服するために、CodeRabbitは大規模な変更セットのレビューを可能にするマルチLLM、および複数ステージのアプローチを採用しています。AIによるコード補完ツールとは異なり、コードレビューはもっと複雑です。レビュアーは、明らかな問題を指摘するだけでなく、プルリクエスト全体のコンテキストや、複数のファイルにわたる変更を理解する必要があります。そのため、レビュアーが必要とする情報量は、開発者がコードを書く際の情報量よりもはるかに多くなります。ここでは、CodeRabbitの設計において直面した課題と、それを解決するためのアプローチを紹介します。
文脈ウィンドウのサイズ
LLMのコンテキストウィンドウ(1回のリクエストで処理できるテキストの範囲)は限られています。たとえば、gpt-3.5-turbo では4Kまたは16Kトークン、gpt-4 では8Kトークンが上限です。これでは大きな変更を処理するには不十分な場合があります。そこで、各ファイルの変更を段階的にレビューし、要点を要約して、より重要な情報を優先的に処理する仕組みを導入しました。
構造化コンテンツの入力と出力
LLMは、構造化されたデータや数学的な計算の処理が苦手です。そのため、標準的なdiff形式ではなく、より人間が理解しやすい形式でコードの変更を処理する方法を開発しました。また、LLMに適切な結果を生成させるため、少数の例文を提供しながら学習を促すアプローチを採用しています。
ノイズの排除
LLMは、重要な情報(シグナル)と不要な情報(ノイズ)の区別が苦手です。例えば20件のレビュー提案を生成しても、その中で有益なのは一部に限られることが多く、コードレビューにおいては特にこの手の問題が顕著です。そこで、CodeRabbitはノイズを除去・シグナルを強化する多段階のレビュープロセスを設計しました。
コストの最適化
高度なモデル(gpt-4 など)は精度が高い一方で、 gpt-3.5-turbo と比較するとコストが数倍以上かかります。そのため、CodeRabbitでは、要約にはシンプルなモデルを使用し、複雑なコードレビューには高性能なモデルを適用する、マルチモデル戦略を採用しました。また、単純なモデルを「トリアージフィルター」として活用し、より詳細なレビューが必要な変更だけを高性能なモデルで処理する仕組みを取り入れています。
不正確な出力への対応
LLMは完全ではなく、不正確な結果を返すことがあります。場合によっては、指示を無視して誤った情報を生成する場合もあります。この問題に対処するため、CodeRabbitには健全性チェックのレイヤーを設け、誤った情報を修正、または削除する仕組みを導入しました。
データプライバシーの確保
開発者にとって最も重要な懸念の一つは、コードがクラウドに保存されたり、モデルのトレーニングに使用されたりするのではないかという点です。CodeRabbitでは、LLMへのクエリは一時的なものであり、データはサービスから即座に削除される設計になっています。同時に、データを保存せずにインクリメンタルなレビューを提供する必要があるため、すべてのステート情報はプルリクエスト内に保存し、CodeRabbitのサーバーには一切残らないシステムを構築しました。
まとめ
LLMの発展は、新しいソフトウェア空間の構築と似ています。かつてMS-DOSがIBM PCやIntelのマイクロプロセッサ上で開発されたように、現在のLLMも制約のある環境で革新を進めています。初期PCが限られたメモリの中でキラーアプリケーションを生み出したように、LLMのコンテキストサイズ制限も技術的な工夫によって克服できる可能性があります。
例えば、初期の3Dゲームは、当時のPCの性能を最大限に活用し、革新的な技術によって動作していました。同じように、LLMを活用して洗練されたアプリケーションを構築するには、新たなアプローチが求められます。LLMやAIインフラ(ベクトルデータベースなど)が一般化するにつれ、付加価値を持つアプリケーションが大きな競争力を持つようになるでしょう。加えて、モデルのトレーニングとプロンプト設計の境界も曖昧になりつつあります。少数の例文を用いたプロンプト設計や微調整が結果の質を大きく影響し、LLMを活用した製品の差別化要素となるのです。
CodeRabbitは、AIを最優先する開発者向けツール企業として、この革新の最前線に立っています。私たちの技術は、Linterや静的コード解析ツールとは異なるアプローチで設計されており、根本的視点から問題を再考しています。AIには依然として限界がありますが、それを超えた実用性を実現したことで、ソフトウェア開発における新たな転換点を迎えています。今後も限界を克服しながら、AIの可能性を押し広げる革新的な製品を提供していきます。CodeRabbitのロードマップには大きな可能性があり、近い将来、開発者にこれまでにない価値を届けられるであろうと楽しみにしています。